This website accompanies the ISMIR 2024 paper entitled "Generating Sample-Based Musical Instruments Using Neural Audio Codec Language Models." Here, we provide listening examples of the instruments generated by the model described in the paper.
System Overview
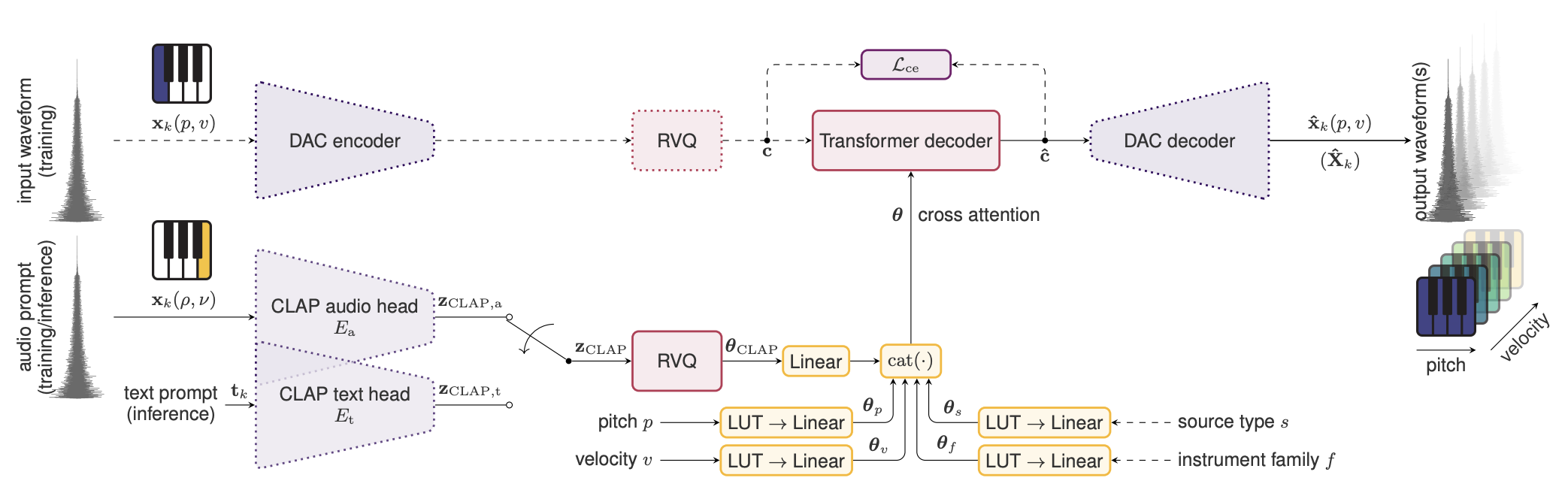
Abstract
In this paper, we propose and investigate the use of neural audio codec language models for the automatic generation of sample-based musical instruments based on text or reference audio prompts. Our approach extends a generative audio framework to condition on pitch across an 88-key spectrum, velocity, and a combined text/audio embedding. We identify maintaining timbral consistency within the generated instruments as a major challenge. To tackle this issue, we introduce three distinct conditioning schemes. We analyze our methods through objective metrics and human listening tests, demonstrating that our approach can produce compelling musical instruments. Specifically, we introduce a new objective metric to evaluate the timbral consistency of the generated instruments and adapt the average Contrastive Language-Audio Pretraining (CLAP) [1] score for the text-to-instrument case, noting that its naive application is unsuitable for assessing this task. Our findings reveal a complex interplay between timbral consistency, the quality of generated samples, and their correspondence to the input prompt.
Text-to-Instrument
MIDI Examples
Here, we showcase the text-to-instrument capabilities of the proposed system. We used five distinct MIDI samples and rendered them using the outputs of the respective models to underscore the variations in their respective characteristics.
| Prompt | Baseline CLAP | Random CLAP | Fixed CLAP |
| Bright acoustic guitar | |||
| Distorted synth bass | |||
| Warm and analog sounding pad that feels like floating in space among stars | |||
| Staccato piano notes with a synthesized bite, echoing like a computer’s rapid calculations | |||
| A string ensemble characterized by high harmonics, light bowing, and sparse vibrato, yielding an airy, floating tonal quality |
Chromatic Scales
Here, we show the text-to-instrument capabilities of the system, by generating chromatic scales of different text-prompts. The velocity can be changed by using the drop-down menu below for comparison.
| Prompt | Baseline CLAP | Random CLAP | Fixed CLAP |
| A bass synth with a distorted sawtooth waveform and high resonance, delivering a gritty, aggressive sonic texture | |||
| A string ensemble characterized by high harmonics, light bowing, and sparse vibrato, yielding an airy, floating tonal quality | |||
| Aggressive and punchy bass that sounds like a dragon's growl echoing in a cavern | |||
| Aggressive and punchy wobble bass that sounds like a dragon's growl echoing in a cavern | |||
| Aggressive synth lead | |||
| Bright acoustic guitar | |||
| Bright upright piano | |||
| Dark concert grand piano | |||
| Deep punchy sub bass | |||
| Distorted electric guitar lead | |||
| Distorted synth bass | |||
| Ethereal and delicate string ensemble that feels like floating in space among stars | |||
| Gritty and aggressive bass synth that sounds like a roaring monster in a dark alley | |||
| Hammond organ | |||
| Lush synth pad | |||
| Metallic vibraphone | |||
| Piano fused with glitchy electronics, creating a sense of urgency and modern chaos | |||
| Pizzicato violin | |||
| Resonant marimba | |||
| Rhodes | |||
| Silky violin | |||
| Staccato piano notes augmented with a synthetic overlay and digital delay, producing a crisp, rhythmically precise tonal effect | |||
| Staccato piano notes with a synthesized bite, echoing like a computer's rapid calculations | |||
| Warm and analog sounding pad that feels like floating in space among stars | |||
| Warm cello |
Sample-to-Instrument
Our system inherently accommodates a sample-to-instrument functionality, whereby a musical instrument can be generated from a single audio reference as input.NSynth Reconstruction
Here, we demonstrate the sample-to-instrument capabilities of the proposed system by showing the sample reconstruction quality of 10 different samples from the test split of the NSynth [2] dataset. These are balanced with respect to instrument family. Please note, that we randomly draw the pitch and velocity for the audio prompt to closely match the real-world use case.
| Prompt Filename/ Target Filename |
Audio Prompt | Target | Baseline CLAP | Random CLAP | Fixed CLAP | Non-autoregressive (baseline CLAP) |
| bass_electronic_018-037-050/ bass_electronic_018-027-075 |
||||||
| brass_acoustic_006-027-100/ brass_acoustic_006-025-025 |
||||||
| flute_acoustic_002-077-100/ flute_acoustic_002-083-100 |
||||||
| guitar_acoustic_021-045-025/ guitar_acoustic_021-072-127 |
||||||
| keyboard_acoustic_004-058-127/ keyboard_acoustic_004-039-100 |
||||||
| mallet_acoustic_047-107-127/ mallet_acoustic_047-084-075 |
||||||
| organ_electronic_001-060-127/ organ_electronic_001-046-050 |
||||||
| reed_acoustic_011-076-100/ reed_acoustic_011-035-127 |
||||||
| string_acoustic_012-040-100/ string_acoustic_012-042-050 |
||||||
| vocal_synthetic_003-088-025/ vocal_synthetic_003-063-025 |
Real-world example
Here, we notionally demonstrate the sample-to-instruent capability with an out-of-domain audio sample used as the prompt for the baseline CLAP conditioning scheme.
| Prompt | Generated audio (2 octaves) |
References
[1] Y. Wu, K. Chen, T. Zhang, Y. Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Jun. 2023.
[2] J. Engel, C. Resnick, A. Roberts, S. Dieleman, D. Eck, K. Simonyan, and M. Norouzi, “Neural audio synthesis of musical notes with WaveNet autoencoders,” in Proceedings of the International Conference on Machine Learning, Aug. 2017.